Interested in learning ArcPy? check out this course.
In this post I will use the PyShp library along with the PyProj library to reproject the local authority boundaries of Ireland, in Shapefile format, from Irish Transverse Mercator to WGS 84 using Python.
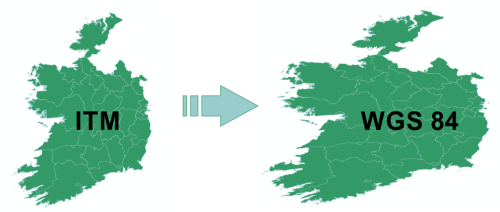
To follow along download the admin boundaries from the Central Statistics Office (CSO) and rename the files to Ireland_LA. Move the files to directory that you want to work from.
You will need to install the libraries, you can use easy install or pip by opening up the command prompt window and entering
easy_install pyshp
easy_install pyproj
or
pip install pyshp
pip install pyproj
Open an interactive Python window and enter the following to make sure that you have access to the libraries.
>>> import shapefile
>>> from pyproj import Proj, transform
If no errors are returned you are good to go.
My original attempt at converting the data lead to this monstrosity…
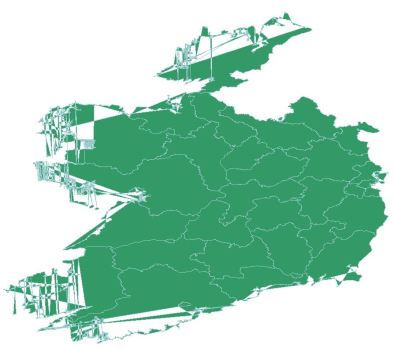
and I instantly realised that several local authority boundaries were made up of multipart geometry.
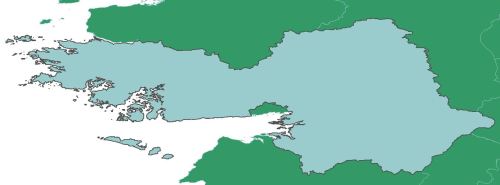
We would need two constructs, one for rebuilding single geometry features and one for rebuilding multipart geometry features.
So let’s get to it. In your favourite Python IDE open a new script, import the libraries and save it. There is a link at the bottom of the post to download the code.
import shapefile
from pyproj import Proj, transform
Define a function to create a projection (.prj) file. See the post on Generating a Projection (.prj) file using Python for more info.
def getWKT_PRJ (epsg_code):
import urllib
wkt = urllib.urlopen("http://spatialreference.org/ref/epsg/{0}/prettywkt/".format(epsg_code))
remove_spaces = wkt.read().replace(" ","")
output = remove_spaces.replace("\n", "")
return output
Define a path to your working directory where the Ireland_LA files reside. You can create a similar path to mine below or define your own, just make sure the Shapefile is located there.
shp_folder = "C:/blog/pyproj/shp/"
Using PyShp create a Reader object to access the data from the Ireland_LA Shapefile.
shpf = shapefile.Reader(shp_folder + "Ireland_LA.shp")
Create a Writer object to write data to as a new Shapefile.
wgs_shp = shapefile.Writer(shapefile.POLYGON)
Set variables for access to the field information of both the original and new Shapefile.
fields = shpf.fields
wgs_fields = wgs_shp.fields
We will grab all the field info from the original and copy it into the new. The ‘Deletion Flag’ as set in the Shapefile standard will be passed over (the tuple in the if statement), and we want data from the lists that follow the tuple that define the field name, data type and field length. Basically we are simply replicating the field structure from the original into the new.
for name in fields:
if type(name) == "tuple":
continue
else:
args = name
wgs_shp.field(*args)

Now we want to populate the fields with attribute information. Create a variable to access the records of the original file.
records = shpf.records()
Copy the records from the original into the new.
for row in records:
args = row
wgs_shp.record(*args)
In the above snippet the args variable holds each record as a list and then unpacks that list as arguments in wgs_shp.record(attr_1, attr_2, attr_3….), which creates a record in the dbf file.
We now have all the attribute data copied over. Let’s begin the quest to convert the data from ITM to WGS84! Define the input projection (the projection of the original file), and an output projection using PyProj..
input_projection = Proj(init="epsg:29902")
output_projection = Proj(init="epsg:4326")
We need to access the geometry of the features in the original file so give yourself access to it.
geom = shpf.shapes()
Now we loop through each feature in the original dataset, access every point that makes up the geometry, convert the coordinates for each point and re-assemble transformed geometry in the new Shapefile. The if statement will handle geometry with only one part making up the feature.
for feature in geom:
# if there is only one part
if len(feature.parts) == 1:
# create empty list to store all the coordinates
poly_list = []
# get each coord that makes up the polygon
for coords in feature.points:
x, y = coords[0], coords[1]
# tranform the coord
new_x, new_y = transform(input_projection, output_projection, x, y)
# put the coord into a list structure
poly_coord = [float(new_x), float(new_y)]
# append the coords to the polygon list
poly_list.append(poly_coord)
# add the geometry to the shapefile.
wgs_shp.poly(parts=[poly_list])
The else statement handles geometries with multi-parts.
else:
# append the total amount of points to the end of the parts list
feature.parts.append(len(feature.points))
# enpty list to store all the parts that make up the complete feature
poly_list = []
# keep track of the part being added
parts_counter = 0
# while the parts_counter is less than the amount of parts
while parts_counter < len(feature.parts) - 1:
# keep track of the amount of points added to the feature
coord_count = feature.parts[parts_counter]
# number of points in each part
no_of_points = abs(feature.parts[parts_counter] - feature.parts[parts_counter + 1])
# create list to hold individual parts - these get added to poly_list[]
part_list = []
# cut off point for each part
end_point = coord_count + no_of_points
# loop through each part
while coord_count < end_point:
for coords in feature.points[coord_count:end_point]:
x, y = coords[0], coords[1]
# tranform the coord
new_x, new_y = transform(input_projection, output_projection, x, y)
# put the coord into a list structure
poly_coord = [float(new_x), float(new_y)]
# append the coords to the part list
part_list.append(poly_coord)
coord_count = coord_count + 1
# append the part to the poly_list
poly_list.append(part_list)
parts_counter = parts_counter + 1
# add the geometry to to new file
wgs_shp.poly(parts=poly_list)
Save the Shapefile
wgs_shp.save(shp_folder + "Ireland_LA_wgs.shp")
And generate the projection file for it.
prj = open(shp_folder + "Ireland_LA_wgs.prj", "w")
epsg = getWKT_PRJ("4326")
prj.write(epsg)
prj.close()
Save and run the file. Open the Shapefile in a GIS to inspect. Have a look at the attribute table, nicely populated with the data. You should be able to configure the code for other polygon files, just change the original input Shapefile, set the projections (input and output), and save a new Shapefile. Also don’t forget the projection file!
You can download the source code for this post here. Right-click on the download link on the page, select Save file as…, before saving change the .txt in the filename to .py and save.
If anyone sees a way to make the code more efficient please comment, your feedback is appreciated.
Resources
For more information on the PyShp library visit documentation here and for PyProj.
Recommended Further Reading
Learning Geospatial Analysis with Python. Visit http://geospatialpython.com/ to get a 50% discount code. But hurry, the deal ends Jan 31, 2016.
CSV to Shapefile with PyShp
Generate a Projection (.prj) file using Python








