Interested in learning ArcPy? check out this course.
Make sure to read the What is Hotspot Analysis? post before proceeding with this tutorial. This tutorial will serve as an introduction to hotspot analysis with ArcGIS Desktop. You will find links at the bottom of the post that will provide information for further research.
Get the Data
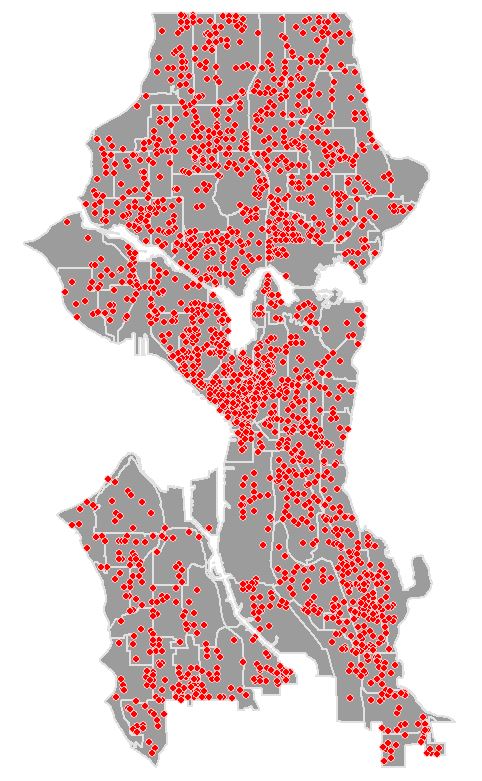
It is often difficult to find real data for use with tutorials so first of all a hat tip to Eric Pimpler, the author of ArcGIS Blueprints, for pointing me towards accessing crime data for Seattle. To follow this tutorial you will need the neighborhoods of Seattle Shapefile which you can download from here and burglary data for 2015 which I have provided a link to here. Use the Project tool from Data Management Tools > Projections and Transformations to project the data into a Projected Coordinate System. For this tutorial I have used UTM Zone 10N. Open, view and if you want style the data in ArcMap.
Spatial Autocorrelation: Is there clustering?
The presence of spatial clustering in the data is a requisite for hotspot analysis. Moran’s I is a measure of spatial autocorrelation that returns a value ranging from -1 to 1. Perfect dispersion at -1, complete random arrangement at 0, and a north/south divide at +1 indicating perfect correlation.

For statistical hypothesis testing, Moran’s I value can be transformed to a z-zcore in which values greater than 1.96 or smaller than -1.96 indicate spatial autocorrelation that is significant at the 5% level.
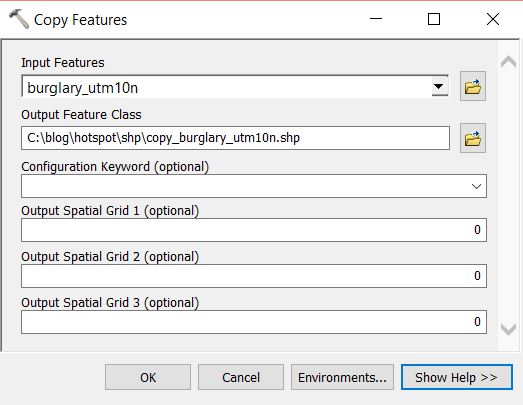
We first need to prepare the data. At the moment each point represent one incident, we need to aggregate the data in some way so that each feature has an attribute with a value in a range. Open the Copy Features tool from Data Management Tools > Features. Create a copy of the burglary point layer. Run the tool and add the new layer to the map.
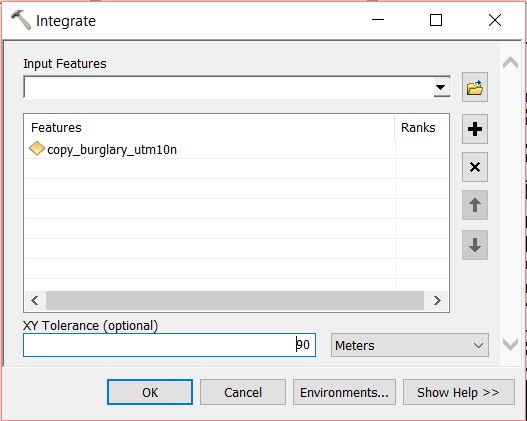
Open the Integrate tool from Data Managemant Tools > Feature Class. Select the copy of the burglary layer as the Input Features and set an XY Tolerance of 90 or 100 meters. Run the tool. This will relocate points within 90m (or 100m) or whatever you set in XY Tolerance field, of each other and stack them on top of one another.
At this moment each point sits on top of another. We need to merge coincident points and make a count of how many were merged at each point. Open the Collect Events tool from Spatial Statistics Tools > Utilities. Set the copy of the burglary layer as the Input Incident Features and set a filepath and name for the Output Weighted Point Feature Class. Run the tool.
The data will be added to the map with graduated symbols, however, we are interested in running further analysis using Moran’s I. If you open the attribute table for the layer you will see a field has been added called ICOUNT. This field holds the count of cooincident points from the Intergrate layer. Open the Spatial Autocorrelation (Moran’s I) from Spatial Statistics Tools > Analyzing Patterns. Set the aggregated burglary layer as the Input Feature Class and ICOUNT as the Input Field. I have left the default setting for the other parameters (see below).
Run the tool by clicking on OK. A summary will display with statistical findings.
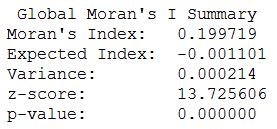
We return a value close to 0.2 and a high z-score. This indicates that clustering exists within the data for high positive values. We are now confident that clustering exists within the dataset and can continue with performing the hotspot analysis.
Optimized Hotspot Analysis
Remove all layers from map the except the two original layers with the burglary data and the neighborhoods. From the Toolbox navigate to Spatial Statistics Tools > Mapping Clusters and open the Optimized Hotspot Analysis tool. This tool allows for quick hotspot analysis using minimal input parameters and sets/calculates default parameters for those you have no control over. For more control over the statistical elements you can use the Hotspot Analysis (Getis-Ord GI*) tool. For now we will use the optimized approach.
Set the burglary points as the Input Features, name your Output Features (here I have named them ohsa_burg_plygns), select COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS for the Incident Data Aggregation Method and choose the neighborhoods features for the Polygons For Aggregating Incidents Into Counts.

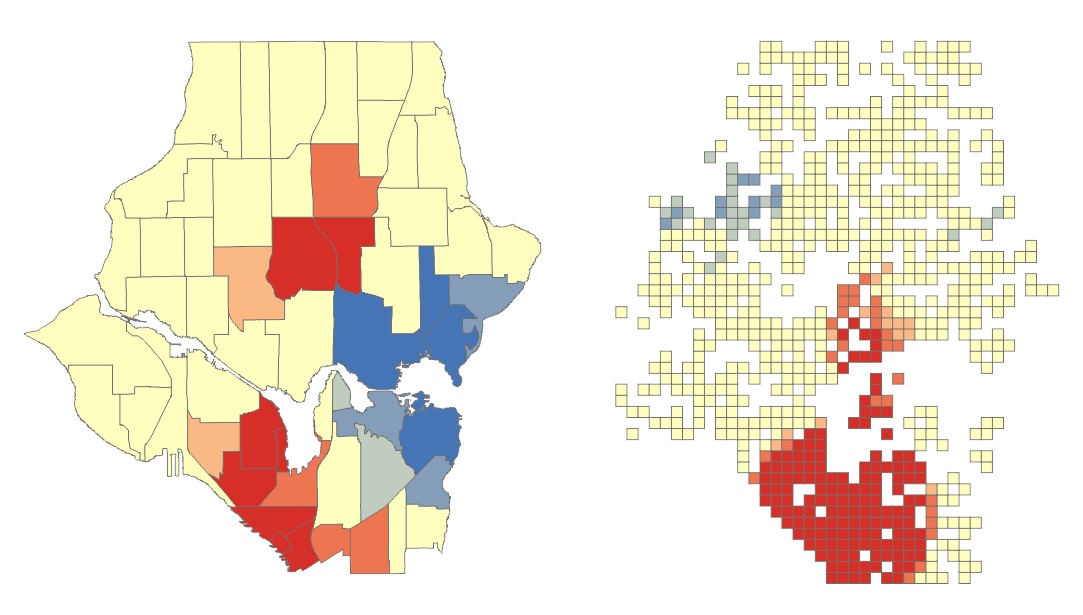
OHSA: Aggregating Point Data to Polygon Features
Click OK to run the tool. The ohsa_burg_plygns layer will automatically be added as a layer to the map, if not, add it and turn off all other layers. So what has happened here? The tool has aggregated the point data into the neighborhood polygons. If you open the attribute table for the newly created layer you will see a field names Count_Join which is a count of burglaries per neighborhood. A z-score and a p-score is calculated which enables the detection of hot and cold spots in the data. Remember, a high z-score and a low p-value for a feature indicates a significant hotspot. A low negative z-score and a small p-value indicates a significant cold spot. The higher (or lower) the z-score, the more intense the clustering. A z-score near 0 means no spatial clustering.

The Gi_Bin field classifies the data into a range from -3 (Cold Spot – 99% Confidence) to 3 (Hot Spot – 99% Confidence), with 0 being non-significant, just take a look at your Table of Contents.

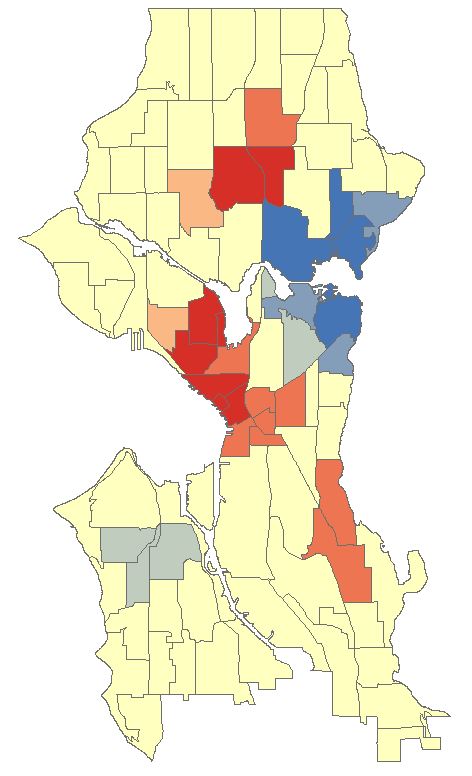
The map should look similar to below. There are several neighborhoods that are statistically significant hotspots. It is important to note that you may need to factor in other data or normalise your data to refine results. Some of the neighborhoods might be densely populated with suburban housing while in others housing may be sparse and bordering towards rural. This may affect findings and you may need to create ratios before analysing. We won’t delve into this here as this tutorial is introductory level (and because I don’t have the data to do so).
OHSA: Aggregating Point Data to Fishnet Features
Close any attribute tables and turn off all layers in your map. Re-open the Optimized Hotspot Analysis tool and set the input as seen below. This time we will create a fishnet/grid to aggregate the point data to.
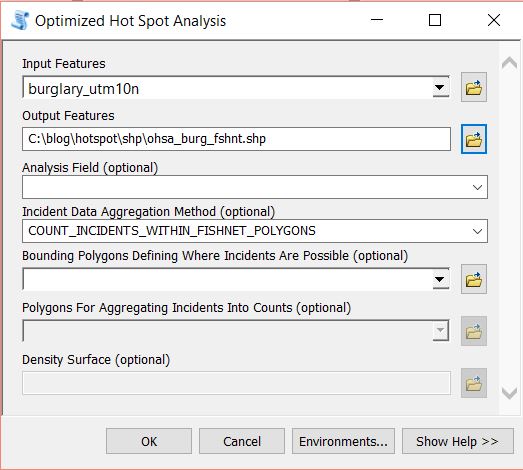
Click OK to run the tool. The tool removes any locational outliers, calculates a cell size, and aggregates the point data to the cells in the grid. Similar to aggregating to polygons the fishnet attribute table will have a join count, z-score, p-score and bin value with the same confidence levels.
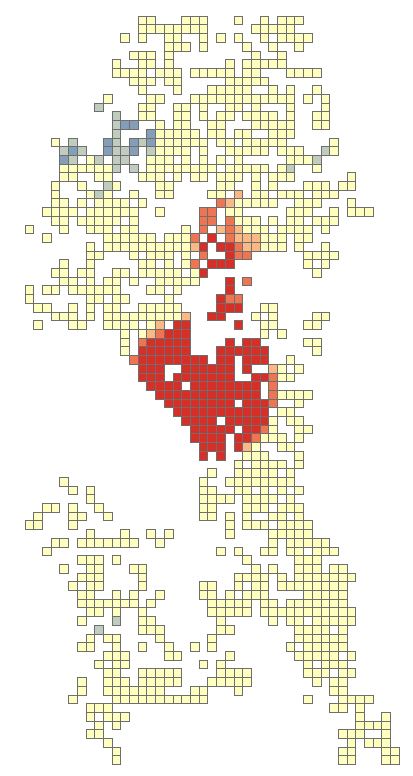 Should attention be entirely focused on the red areas? Copy the fishnet layer and paste it into the data frame. Rename the copy as fishnet_count. Open the properties and navigate to the Symbology tab. Change the Value field to Join_Count, reduce the Classes to 5 and set the classification to Equal Count. Click OK.
Should attention be entirely focused on the red areas? Copy the fishnet layer and paste it into the data frame. Rename the copy as fishnet_count. Open the properties and navigate to the Symbology tab. Change the Value field to Join_Count, reduce the Classes to 5 and set the classification to Equal Count. Click OK.
 There will be one red cell and one light red cell in the northern half of the map. Use the zoom tool to zoom-in closer to both features. Turn on the labels for the feature for the Join_Count attribute. Notice that the light-red cell has a count of 19 but in the Hotspot Analysis this was a non-significant area. With the second highest burglary count for a 300m x 300m area surely this area requires some attention. Perhaps all areas outside of significant hotspots with values greater that 15 are a priority? I am not a expert in crime analysis so I’ll leave it up to those sleuth’s.
There will be one red cell and one light red cell in the northern half of the map. Use the zoom tool to zoom-in closer to both features. Turn on the labels for the feature for the Join_Count attribute. Notice that the light-red cell has a count of 19 but in the Hotspot Analysis this was a non-significant area. With the second highest burglary count for a 300m x 300m area surely this area requires some attention. Perhaps all areas outside of significant hotspots with values greater that 15 are a priority? I am not a expert in crime analysis so I’ll leave it up to those sleuth’s.
This just serves to note to make sure that you use all the analysis techniques at your disposal from simple to more advanced, from visual and labels to statistical.
OHSA: Create Weighted Points by Snapping Nearby Incidents
Zoom out to the full extent of the neighborhoods layer and turn off all layers in the map. Re-open the Optimized Hotspot Analysis tool and set the input as seen below. Notice this time we will also create a Density Surface.

Click OK and run the tool. The tool calculates a distance value and converges points that fall within that distance in relation to each other. It then runs the hotspot analysis similar to the previous two examples producing an attribute table with an ICOUNT field, z-score, p-score and bin value for confidence level. The ICOUNT field denotes how many incidents the one point references.

Let’s clip the density raster to the neighborhoods layer. Open the Clip tool from Data Management Tools > Raster > Raster Processing. Set the Input Raster as the density raster, use the neighborhoods layer as the Output Extent, make sure Use Input Features for Clipping Geometry is checked, set and name the Output Raster Dataset.

Click OK and run the tool. Add the newly created raster to the map if it hasn’t automatically been added. Make it the only visible layer. Open the properties for the layer and go to the Symbology tab. Select Classified and generate a histogram if asked to. Change the Classes to 7 and the colour ramp to match previous colour schemes. You might need to flip the colour ramp to achieve this.
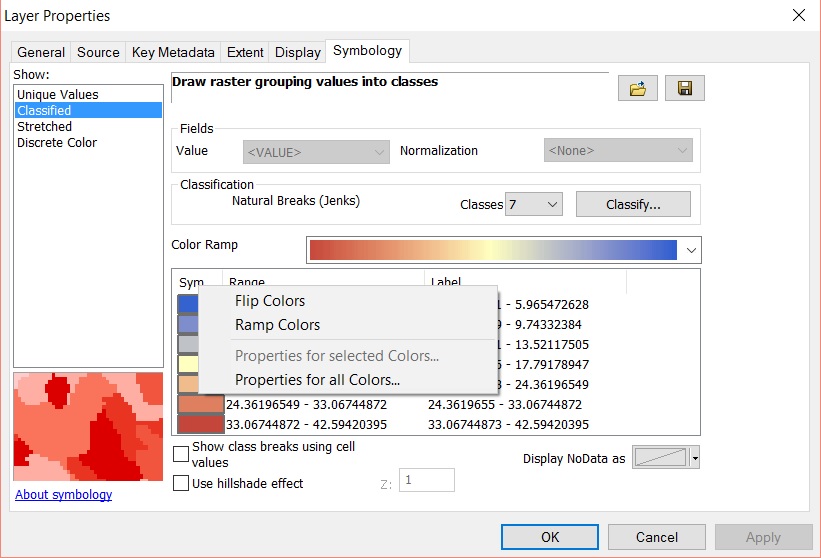
Open the Display tab and select Bilinear Interpolation from Resample during display dropdown menu. This will smoothen the contour look of the raster. Click OK to view the density surface. Turn on the neighborhoods and make the fill transparent with a black outline.
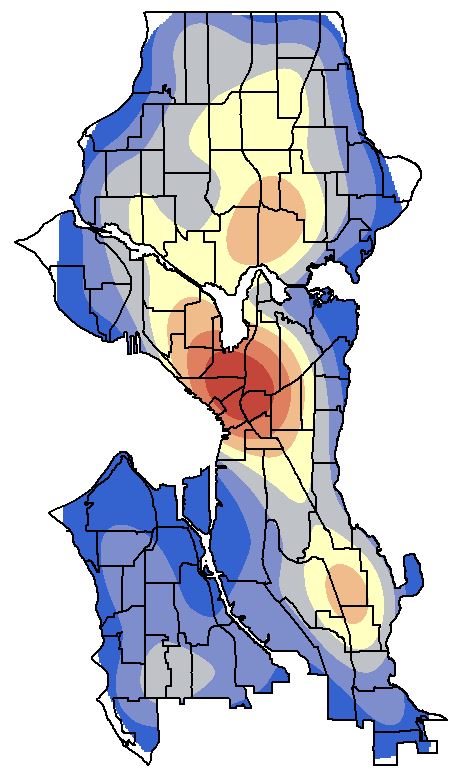
Alternatives
The Optimized Hotspot Analysis tool is a great place to start but it limits the analysis to default parameters set by the tool or calculated by the tool. For more advanced user control you can use the Hotspot Analysis (Getis-Ord Gi*) tool. You will need to use other tools such as Spatial Join to aggregate your data to polygons and create a Join_Count field, or the Create Fishnet tool to define a grid and then use Spatial Join. Remember to delete any grid cells that have a value of zero prior to running the hotspot analysis.

See the resources below for more information on using Getis-Ord Gi* and what the parameters do especially in relation to the Conceptualization of Spatial Relationships parameter.
Hotspot Analysis with ArcGIS Resources
ArcGIS Optimized Hotspot Analysis
ArcGIS Mapping Cluster Toolset: Hot Spot Analysis
ArcGIS How Hot Spot Analysis Works
ArcGIS – Selecting a Conceptualization of Spatial Relationships: Best Practices
Crime Data for Seattle
Crime data was accessed using the ArcGIS REST API and the Socrata Open Data API from the https://data.seattle.gov website. I highly recommend getting your hands on Eric Pimplers ArcGIS Blueprints eBook for a look at exciting workflows with ArcPy and the ArcGIS REST API.