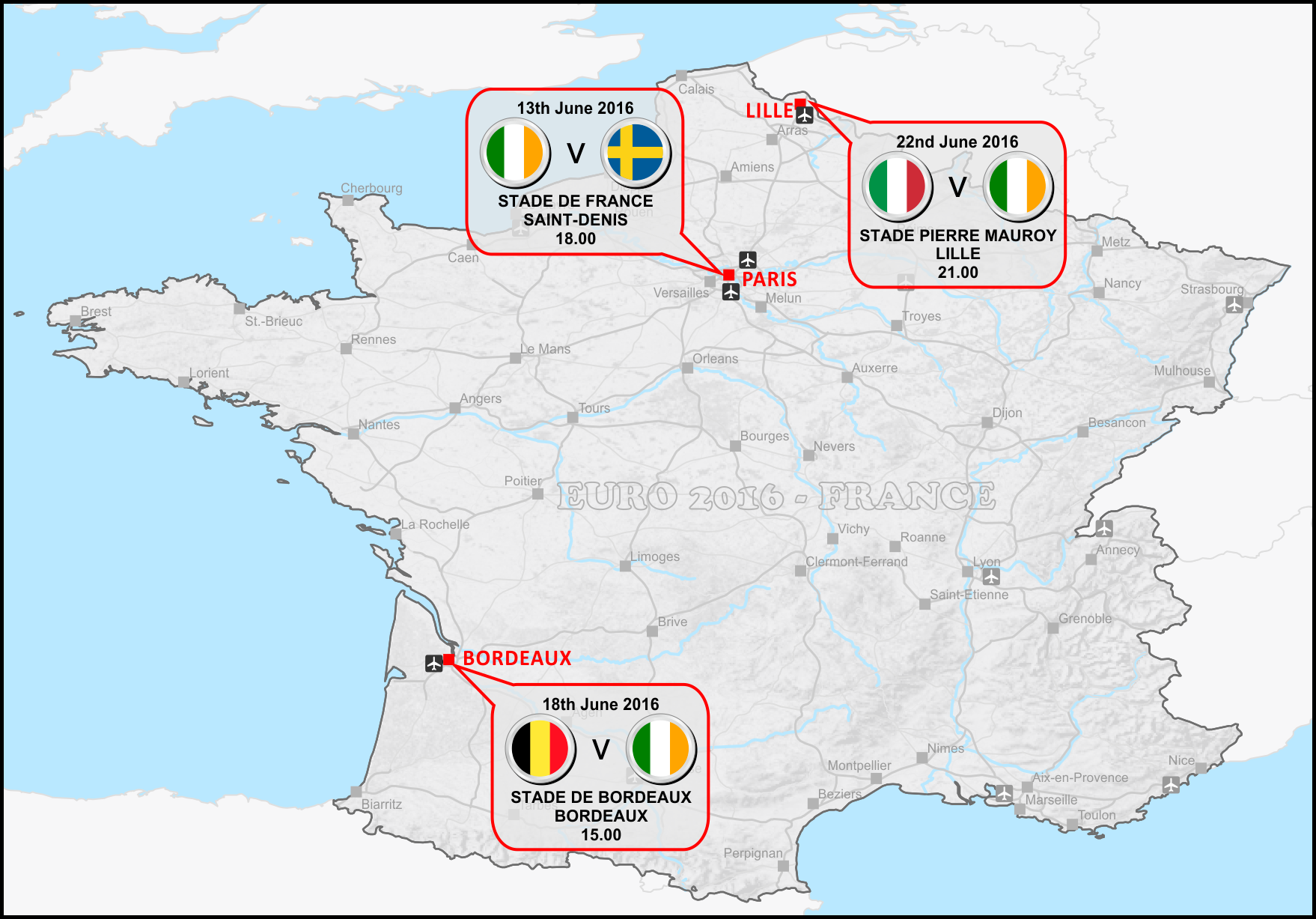
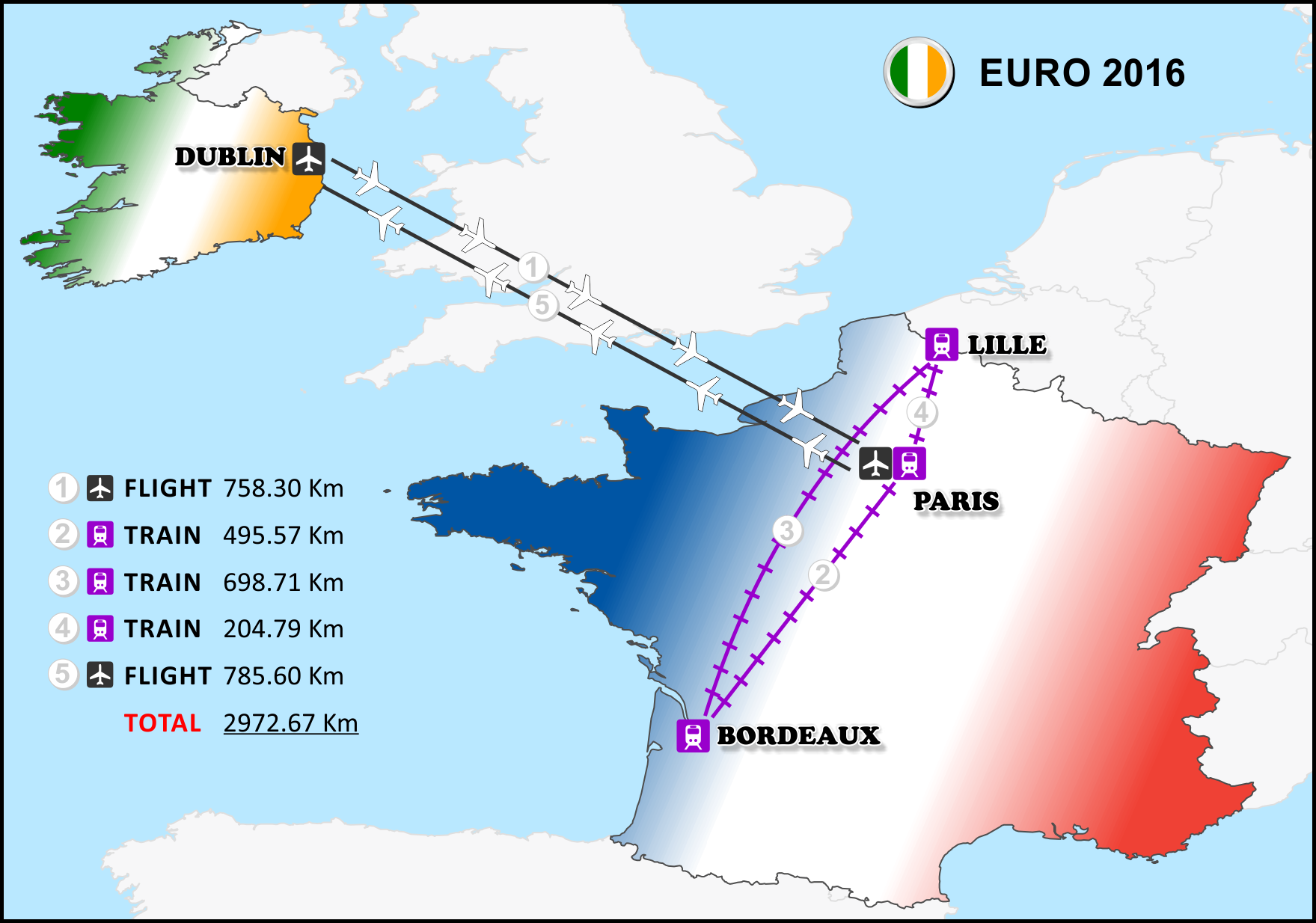
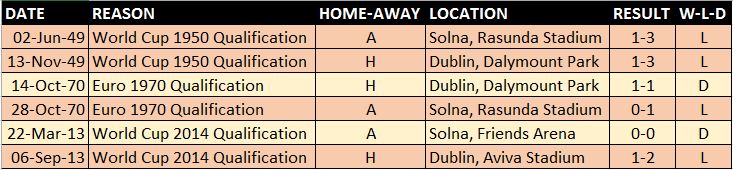
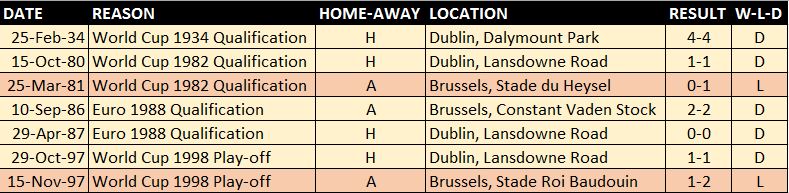
Title: The ESRI Guide to GIS Analysis Vol. 2: Spatial Measurements & Statistics
Author: Andy Mitchell
Publisher: ESRI Press
Year: 2005
Aimed at: GIS/Analysts/Map Designers – intermediate
Purchased from: www.wordery.com

This textbook acts as companion text for GIS Tutorial 2: Spatial Analysis Workbook (for ArcGIS 10.3.x) where you can match up the chapters in each book. Although not a necessity, I would recommend using both texts in tandem to apply the theory and methods discussed with practical tutorials and walkthroughs using ArcGIS. This is the second book of the series and follows on from The ESRI Guide to GIS Analysis Volume 1: Geographic Patterns & Relationships.
The first chapter is, inevitably, an introduction to spatial measurements and statistics. You perform analysis to answer questions and to answer these questions you not only need data but you also need to understand the data. Are you using nominal, ordinal, interval or ratio values, or a combination of these? The type of value(s) will shape the analysis techniques and methods used to calculate the statistics. You will need to interpret the statistics, test their significance and question the results. These elements are briefly visited with the premise of getting more in-depth as the book progresses. The chapter ends with a section on ‘Understanding data distributions’ which is essentially a brief introduction to data exploratory techniques such as describing frequency distributions, spatial distributions, and the presence of outliers and how they can affect analysis.
Chapter 2 discusses measuring geographic distributions with the bulk of the chapter focused on finding the center (mean, meridian, central feature), and measuring compactness (standard distance), orientation and direction of distributions (spatial trends). These are discussed for points, lines, and areal features and also using weighted factors based on attributes. These are useful for adding statistical confidence to patterns derived from a map. Formulas and equations begin to surface and although not necessary to learn them off by heart, because the GIS does all the heavy lifting for you, it gives insight into what goes on under the hood, and knowing the underlying theory and formulas can often aid in troubleshooting and producing accurate analysis. The last section of this chapter is fundamental to the rest of the text, testing statistical significance. This allows you to measure a confidence level for your analysis using the null hypothesis, p-value, and z-score. This can be a difficult topic to comprehend and may require further reading.
The third chapter, a lengthy one, is based around using statistical analysis to identify patterns, to enhance and backup the visual analysis of the map with confidence or to find patterns not may not have been immediately obvious. The human eye will often see patterns that do not really exist, so alternatively, statistical analysis might indicate what you thought was a strong pattern was actually quite weak. The statistical analysis methods are beginning to heat up and here we are introduced to; the Kolmorogov-Smirnov test and Chi Square test for quadrat analysis in identifying patterns in areas of equal size; the nearest neighbour index for calculating the average distance between features and identifying clustering or dispersion; and the K-function as an alternative to the nearest neighbour index, each used to measure the pattern of feature locations. These are followed by measuring the spatial pattern of feature values using; the join count statistic for areas with categories; Geary’s c and Moran’s I for measuring the similarity of nearby features, and the General-G statistic for measuring the concentration of high and low values for features having continuous values. The formulas for each are presented along with testing the significance of and interpreting the results. The final section of this chapter discusses defining spatial neighbourhoods and weights when analysing patterns. There are a few things to consider such as local or regional influences, thresholds of influence, interaction between adjacent features, and the rate of regional decline of influence.
Chapter 4 is titled ‘Identifying Clusters’ with a main focus on hotspot analysis. First, we are introduced to nearest neighbour hierarchical clustering which is heavily used in crime analysis. While Chapter 3 discussed global methods for identifying patterns and returns a single statistic, this chapter focuses on local statistics to show where these patterns exist within the global setting. Geary’s c and Moran’s I both have local versions and their definition, implementation, and factors influencing the results are discussed and critiqued along with Art Getis’ and Keith Ord’s Gi* method for identifying hot and cold spots.While the methods in Chapter 3 enforced that there are patterns in the data (or not), the methods in Chapter 4 highlight where these clustered patterns are. The last section of Chapter 4 discusses using statistics with geographic data; how the very nature of geographic data affects your analysis, how geographic data is represented in a GIS affects your data analysis, the influence of the study area boundary, and GIS data and errors.
“To the extent you’re confident in the quality of your GIS data, you can be confident in the quality of your analysis results.”
The last chapter ventures away from identifying patterns and clusters and focuses on analysing geographic relationships and using statistics to analyse such. Geographic relationships and processes are used to predict where something is likely to occur and examining why things occur where they do. Chapter 5 looks at statistical methods for identifying geographical relationships with a Pearson’s correlation coefficient and Spearman’s correlation coefficient discussed and assessed. Linear regression (ordinary least squares), and geographically weighted regression are presented as methods for analysing geographic processes. These methods warrant a full text in their own right and there is a list of further reading available at the end of the chapter.
Overall Verdict: I feel that I will be referring back to this text a lot. Having recently completed a MSc in Geocomputation I wish that this had crossed my path during the course of my studies and I would highly recommend this book to anyone venturing into spatial analysis where statistics can aid and back up the analysis. Although they are littered throughout the chapters, you really do not need to get bogged down with the formulas behind the statistical analysis techniques, the most important points is that you understand what the methods are performing, their limitations, and how to assess the results and this book really is a fantastic reference for doing just that. Knowing the theory is a huge step to being able to apply the analysis techniques confidently and derive accurate reporting of your data.